Two weeks ago together with Mateusz Fedoryszak I attended the first european Spark Summit (#SparkSummitEU). What did we find there and how did we enrich Spark Community? Let me tell you the story of the summit and Sparkling Ferns...
First of all, yes, Matei Zaharia was excited as usual during his presentation. Second, yes, everyone had been super enthusiastic on every occasion during the Summit. Third, yes, you must attend Spark Summit if you haven’t done it yet. If you have - you know nothing else is even close to this experience. Anyway, we shall meet there next year!
Many attendees asked us about Random Ferns and our implementation of it for Apache Spark: Sparkling-ferns. Let’s go through Random Ferns FAQ. BTW: You may enjoy watching our talk:
Our slides are publically available as well.
1. What are Random Ferns?
Random Ferns is a supervised learning classification algorithm.
In classification algorithms items are described with a feature vector f. We want to label each item using a class c from the set of classes C. To do so we create a model, which takes a vector f and returns c, the most suitable class for the vector f.
Now, there are many ways to do so. We may use Naive Bayes, Random Forests, SVM, etc. or Random Ferns.
2. When should I be interested with Random Ferns?
There are some natural indicators to use a specific algorithm.
With Random Ferns these indicators are:
- requirement to train a model in linear time against the number of items
- requirement to train a model in linear time against the number of features
- plenty of memory to use (Random Ferns model can be quite big, I am going to explain it later)
3. I’ve heard about Random Forests - can you compare it with Random Ferns?
Sure!
3.1. Random Forests
With Random Forests you have many decision trees. Each is trained on some subset of data. Let’s investigate one tree within the forest (see Fig.1.1.). In each node one or more features of an item are tested to choose which child node should be chosen. When you arrive at a leaf node you obtain a class c or list of probabilities for each class from C.
The important things to note are:
- one or more features may be used to choose child node,
- each node has its own test - sibling nodes can use completely different features and/or different thresholds.
The final class c assigned by a model is chosen e.g. by voting on results from particular trees.
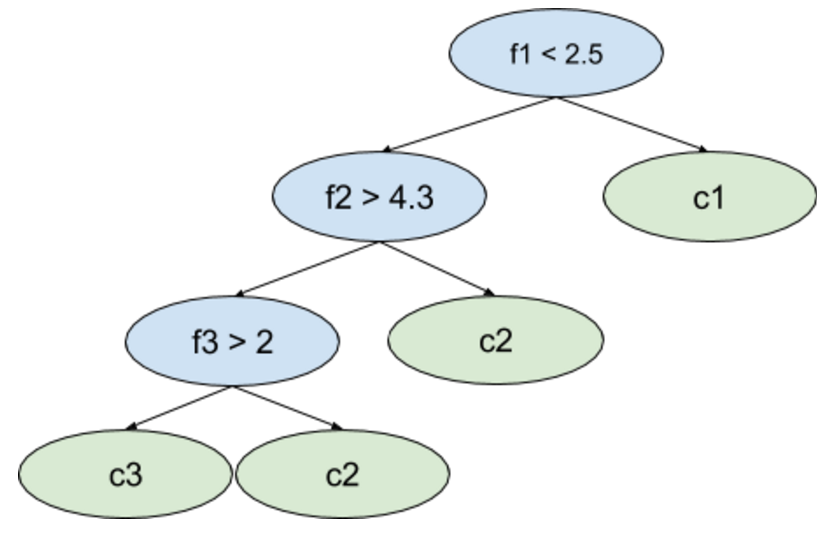 Fig.1.1. The example of a decision tree within a Random Forest model.
Fig.1.1. The example of a decision tree within a Random Forest model.
3.2. Random Ferns
Now, when we use Random Ferns two things are different:
- We are using perfect binary trees, where all levels of a tree are filled (they are balanced), and on each level only one feature is checked.
- Each fern has a threshold set for each feature. As a result on each level the decision if an item's feature passes a threshold can be encoded with a binary value: 0 or 1.
As you can see in Fig.1.2. we have exactly 2^N leafs, where N is the number of features used. We also have C classes. What is more important is that we can enumerate all leafs using bits collected from the root to the chosen leaf. By going from the root to the bottom-left leaf in Fig.1.2. we collect bits 000, which represents the integer number 0. By going to the bottom-right leaf we collect bits 111, which represents number 7.
The natural next step is to switch from the tree representation to the 2D array representation, where leaf code is the first coordinate and a class number is the second coordinate. A value obtained by passing a leaf code and a class number c is probability of correctly labeling an item as a matching to a class c.
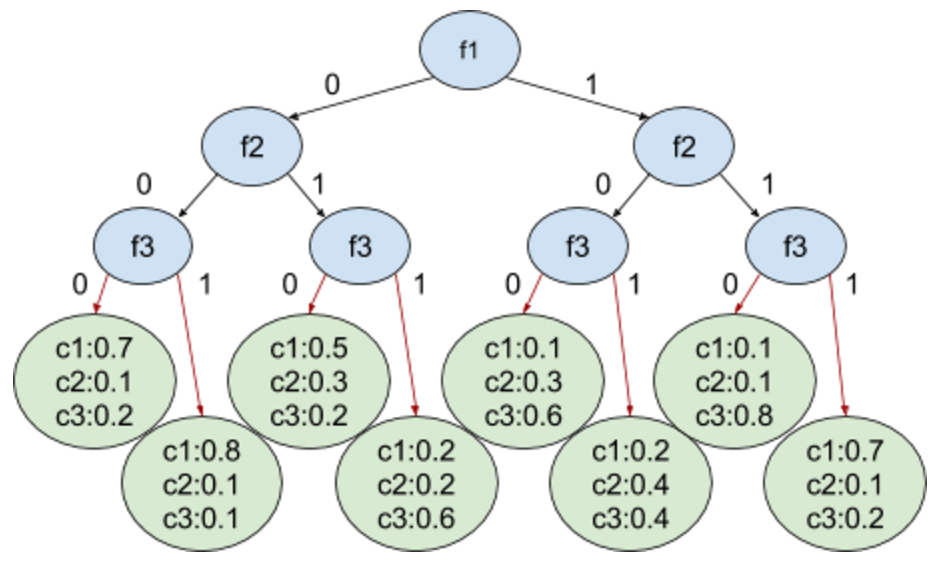
Fig.1.2. The example of a fern (represented as a tree) within a Random Ferns model.
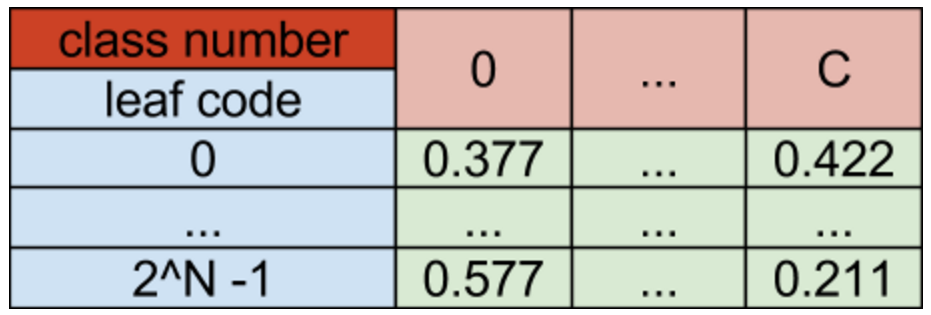
Fig.1.3. The example of a fern (represented as a 2D array) within a Random Ferns model.
4. How big can be a Random Ferns model?
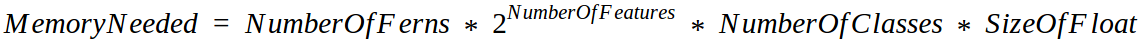
Now let’s use some numbers.
Example 1
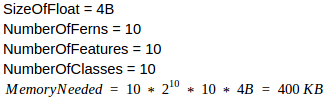
Example 2
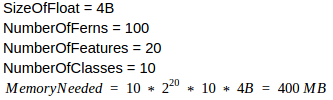
Observation 1: Adding 10 more features to a model makes it 1024 times bigger than the previous one.
Observation 2: Doubling the number of ferns or classes make a new model 2 times bigger than the previous one.
5. How fast can I train Random Ferns model?
During tests checking model creation time the following empirical dependency had been established: 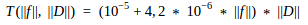
It is easier to think about this dependency in terms of 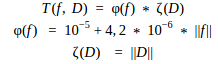
So with a fixed number of features used f a model creation time grows linearly with a growth of a dataset size D. Conversely, with a fixed size of a dataset D a model creation time grows linearly with a growth of a number of features f.
What does it mean? When you are training your model, you can easily predict when it will be ready.
6. How can I “plug” Random Ferns package into Spark?
Use the command:

and enjoy Random Ferns right away!
7. How can I use Random Ferns code in Spark?
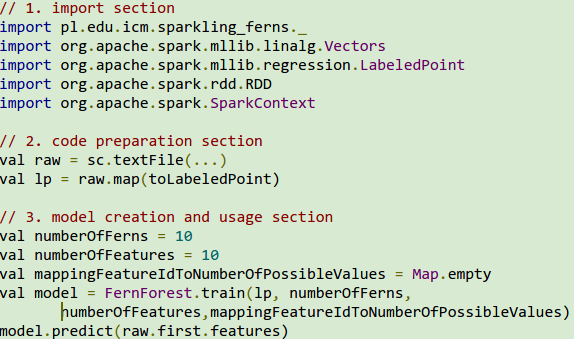
- You should import mllib Vectors and LabeledPoint as well as all classes from the package pl.edu.icm.sparkling_ferns.
- Next you should cast your data into instances of the LabeledPoint class.
- Finally, you should feed the method FernForest.train with LabeledPoint instances. Please pass along also numberOfFerns, numberOfFeatures and the mapping from feature ID to the number of possible values of a feature.
- Having two features, e.g. "doors" and "persons", with possible values (respectively): List("2", "3", "4", "more") and List("2", "4", "more"), the map passed should be: Map(0 -> 4, 1 -> 3)
- If feature values are continuous you should pass an empty map (Map.empty).
8. Where I can find out more about Random Ferns?
For more details consult GitHub or Spark-packages.org. The complete example of the package use is in the test segment of a code.